Krutrim-2: A Best-in-Class Large Language Model for Indic Languages


Krutrim-2 is a 12B parameter multilingual LLM optimized for English and 22 Indic languages, built on the Mistral-NeMo architecture with a 128K token context window. It delivers best-in-class performance on Indic tasks, surpassing models 5-10x its size, and represents a significant leap in Krutrim’s mission to build AI models for India.
Description
The plurality of Indian languages and culture poses unique challenges in building general purpose AI models for India. In the context of large language models, these include multilingual language understanding covering this linguistic diversity and the ability to respond back while honoring the cultural nuances and maintaining a personable conversational tone. Towards that we trained Krutrim-1 - our first multilingual foundational model for India in 2023 and released to the public in Jan 2024. The model delivered promising performance on multiple Indic benchmarks. However, owing to its smaller size (7B parameters) and training on relatively lesser FLOPs, it left a lot to be desired for its users. Given the prevalence of synthetic web data and lesser capacity to alignment - it had a tendency of confirmation bias leading to hallucinations like it was built by other AI labs.
Building upon our foundational work, we now present Krutrim-2, a best-in-class large language model for Indic. The model has been meticulously crafted to cater to various linguistic needs within India and beyond. Krutrim-2 is a 12 billion parameters dense transformer model, built on the Mistral-NeMo architecture. Our team ensured that Krutrim-2 received comprehensive training on a rich dataset encompassing English, Indic languages (hundreds of billions of tokens), code snippets, mathematical concepts, literary works, and high quality synthetically generated content. It is natively multilingual (English and 22 Indian languages) and supports a context window of 128K tokens.
The model delivers best-in-class performance across Indic tasks and a promising performance on English benchmarks equivalent to models 5-10x the size. We present details of the model architecture, pre-training, post-training and evaluation results. We also publicly release the post-trained versions of the model. We are continuously improving the model through post-training techniques such as RLVR.
At Krutrim, we have consistently strived towards creating advanced models capable of understanding, processing, and generating content in multiple languages. With Krutrim-2, our journey takes another significant leap and paves way forward towards our mission to build models for India.
Use Cases
Creative writing and more relevant responses in Indian languages
Krutrim-2 is natively multilingual, delivering state-of-the-art performance on Indic benchmarks. It also matches or outperforms models up to six times larger in multilingual tasks such as creative writing, summarization, and translation.
Long-form generation
The model supports a context window of 128K tokens enhancing its ability to handle extensive inputs and maintain context over longer interactions. This makes it well suited for long-form generation, multi-turn conversations, document translation, coding and others.
Multimodal applications
Its improved multilingual understanding and generation capabilities on Indian languages makes it the model of choice as a backbone in large multimodal models for visual understanding, captioning, and speech applications in the Indian context.
Cost efficient AI applications
With best-in-class performance on Indic, better than or competitive with that of models much larger in size in tasks like coding and instruction following, the model offers a significant cost advantage in integrating it in AI applications for India. Further, the enhanced multilingual understanding and generation capabilities of the model can be distilled into models much smaller in size.
Demo
Engages in multiturn conversation in Indic


Solves math problems in Indic

Explains code in your language
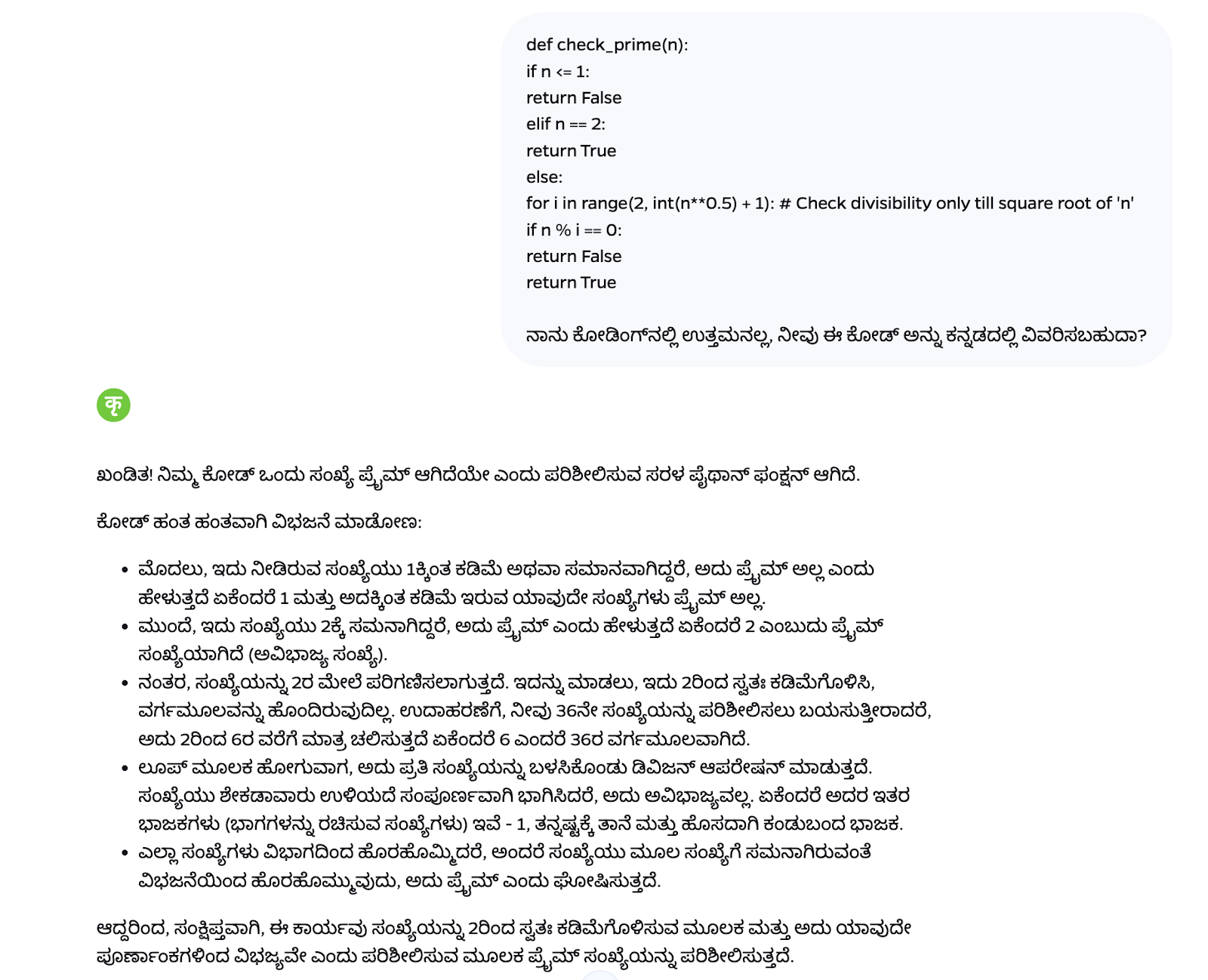
Indian context understanding

Support low-resource languages like Sanskrit

Use it in agentic applications
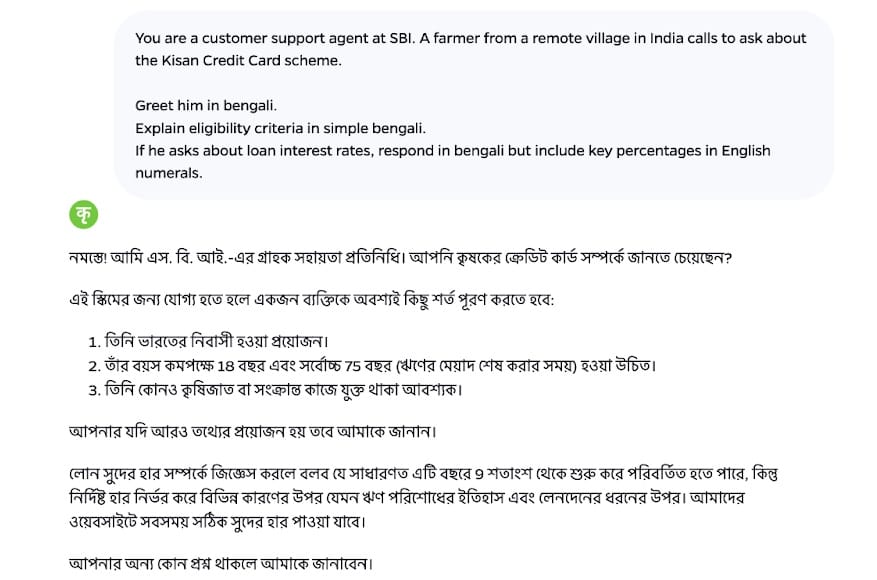
Model Architecture and Training
Krutrim-2 is a 12B parameter dense transformer model based on the Mistral-Nemo architecture. The model is pre-trained on high quality data comprising a curated mix of English, Indic, code, math, books, and synthetic data. It is natively multilingual (English and Indian languages) and supports a context window of 128K tokens. We followed a multi-stage training procedure, varying the data-mix, context size and batch size at every stage, leading to a stable and efficient model training.
After pre-training, the model underwent supervised training for cross-task instruction following and direct preference optimization for alignment.
| # | Hyper parameter | Value |
|---|---|---|
| 1 | Layers | 40 |
| 2 | Max sequence length | 128K |
| 3 | Vocab size | 131K |
| 4 | Attention type | GQA (Group Query Attention) |
| 5 | Positional embeddings | RoPE |
Evaluation
EN Benchmarks
We use the LM Evaluation Harness to evaluate our model on the En benchmarks tasks. Please note that at the time of writing this report, we were unable to use the evaluation framework for llama-3.3-70B, Gemini-1.5-flash and GPT-4o. We currency report the available published numbers for these models. We realise that the prompt templates and few-shot settings might vary and are working to make these evaluations consistent.
| # | Benchmark | Metric | Krutrim-1 7B | MN-12B-Instruct | Krutrim-2 12B | llama-3.3-70B | Gemini-1.5 Flash | GPT-4o |
|---|---|---|---|---|---|---|---|---|
| 1 | Hellaswag (10-shot) Common sense reasoning | Accuracy | 0.74 | 0.85 | 0.84 | 0.95 | 0.87 | 0.95 |
| 2 | CommonSenseQA (0-shot) Common sense reasoning | Accuracy | 0.74 | 0.70 | 0.74 | - | - | 0.85 |
| 3 | TruthfulQA (0-shot) Factuality | Accuracy | 0.49 | 0.54 | 0.59 | - | - | 0.59 |
| 4 | MMLU (5-shot) Language understanding | Accuracy | 0.47 | 0.68 | 0.63 | 0.82 | 0.79 | 0.86 |
| 5 | TriviaQA (5-shot) Reading comprehension | EM | 0.44 | 0.72 | 0.62 | - | - | - |
| 6 | GSM8K (8-shot) Math | EM | 0.07 | 0.78 | 0.72 | 0.93 | 0.86 (11-shot) | 0.89 |
| 7 | ARC_Challenge (25-shot) Knowledge reasoning | Accuracy | 0.48 | 0.66 | 0.65 | 0.93 | - | 0.50 |
| 8 | HumanEval Coding | Pass@10 | 0.00 | 0.23 | 0.80 (Pass@10) | 0.88 | 0.74 (0-shot) | 0.90 |
| 9 | IF_Eval (0-shot) Inst. following | Accuracy | 0.27 | 0.46 | 0.73 | 0.92 | - | 0.84 |
BharatBench
The existing Indic benchmarks are not natively in Indian languages, rather, they are translations of existing En benchmarks. They do not sufficiently capture the linguistic nuances of Indian languages and aspects of Indian culture. Towards that Krutrim released BharatBench - a natively Indic benchmark that encompasses the linguistic and cultural diversity of the Indic region, ensuring that the evaluations are relevant and representative of real-world use cases in India. For more information, please refer to the BharatBench blog.
| # | Benchmark | Metric | Krutrim-1 7B | MN-12B-Instruct | Krutrim-2 12B | llama-3.1-70B-Instruct | Gemma-2-27B-Instruct | GPT-4o |
|---|---|---|---|---|---|---|---|---|
| 1 | Indian Cultural context (0-shot) Generation | Bert Score | 0.86 | 0.56 | 0.88 | 0.88 | 0.87 | 0.89 |
| 2 | Grammar Correction (5-shot) Language understanding | Bert Score | 0.96 | 0.94 | 0.98 | 0.98 | 0.96 | 0.97 |
| 3 | Multi Turn (0-shot) Generation | Bert Score | 0.88 | 0.87 | 0.91 | 0.90 | 0.89 | 0.92 |
| 4 | Multi Turn Comprehension (0-shot) | Bert Score | 0.90 | 0.89 | 0.92 | 0.93 | 0.91 | 0.94 |
| 5 | Multi Turn Translation (0-shot) | Bert Score | 0.85 | 0.87 | 0.92 | 0.91 | 0.91 | 0.92 |
| 6 | Text Classification (5-shot) | Accuracy | 0.61 | 0.71 | 0.76 | 0.88 | 0.86 | 0.89 |
| 7 | Named Entity Recognition (5-shot) | Accuracy | 0.31 | 0.51 | 0.53 | 0.61 | 0.65 | 0.65 |
Indic Benchmarks
We also report the performance of our model on the existing Indic benchmarks - IndicXTREME, IndicGenBench and IN-22 for translation The numbers are averaged across 11 Indic languages - Assamese, Bengali, Gujarati, Hindi, Kannada, Malayalam, Marathi, Oriya, Punjabi, Tamil, Telugu.
| # | Benchmark | Metric | Krutrim-1 7B | MN-12B-Instruct | Krutrim-2 12B | llama-3.3-70B | Gemini-1.5 Flash | GPT-4o |
|---|---|---|---|---|---|---|---|---|
| 1 | IndicSentiment (0-shot) Text classification | Accuracy | 0.65 | 0.70 | 0.95 | 0.96 | 0.99 | 0.98 |
| 2 | IndicXParaphrase (0-shot) Generation | Accuracy | 0.67 | 0.74 | 0.88 | 0.87 | 0.89 | 0.91 |
| 3 | IndicQA (0-shot) Generation | Bert Score | 0.90 | 0.90 | 0.91 | 0.89 | 0.94 | TBD |
| 4 | FloresIN Translation xx-en (1-shot) | chrF++ | 0.54 | 0.50 | 0.58 | 0.60 | 0.62 | 0.63 |
| 5 | FloresIN Translation en-xx (1-shot) | chrF++ | 0.41 | 0.34 | 0.48 | 0.46 | 0.47 | 0.48 |
| 6 | IN22 Translation xx-en (0-shot) | chrF++ | 0.50 | 0.48 | 0.57 | 0.58 | 0.55 | 0.54 |
| 7 | IN22 Translation en-xx (0-shot) | chrF++ | 0.36 | 0.33 | 0.45 | 0.42 | 0.44 | 0.43 |
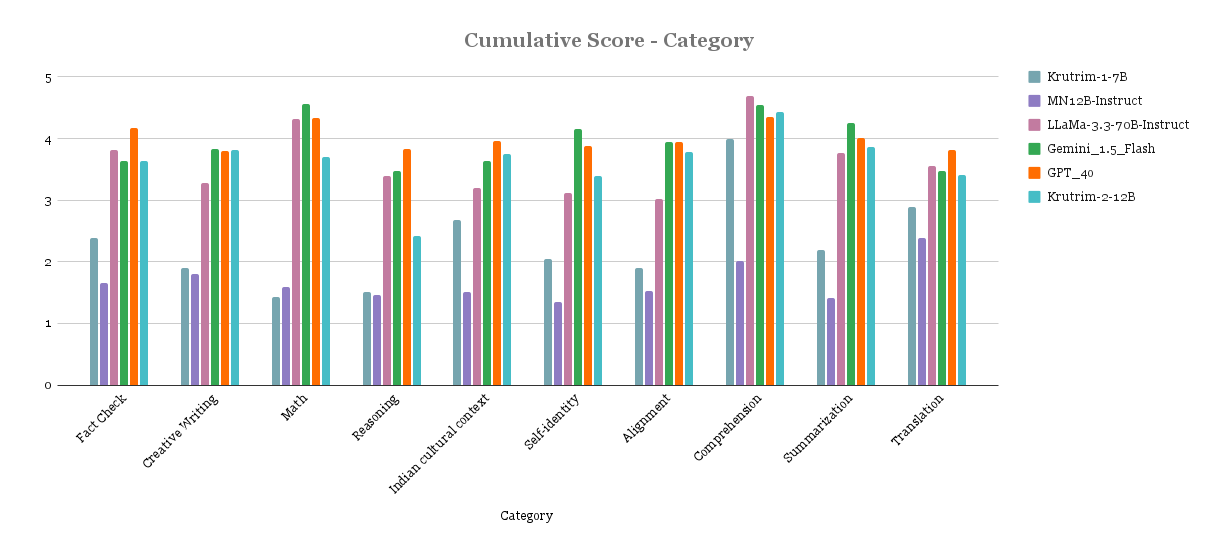
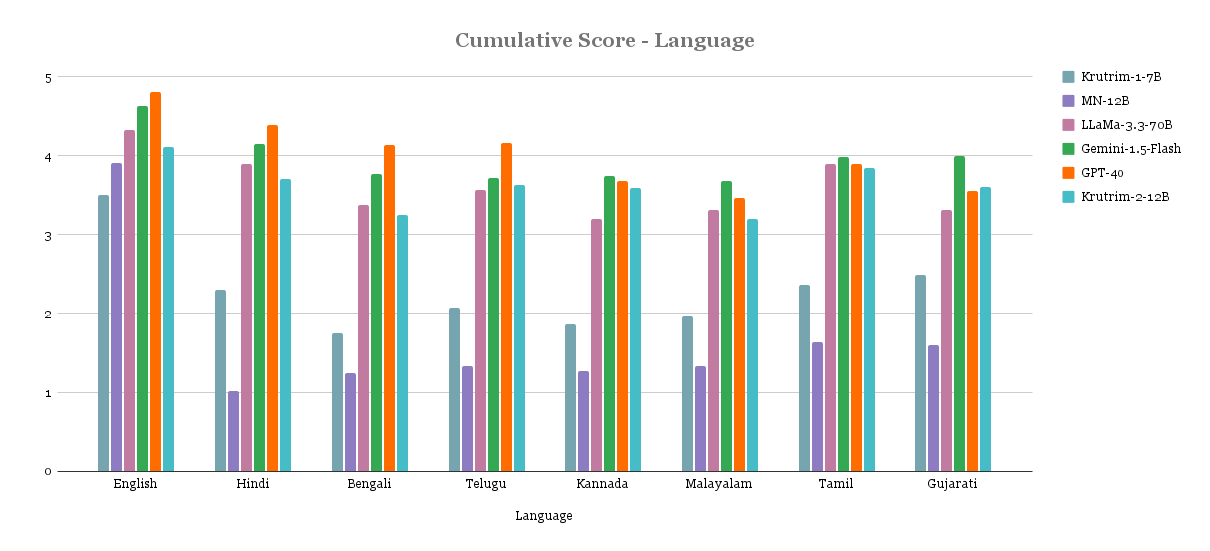
Qualitative Evaluation
In addition to the quantitative evaluations on the academic benchmarks above, we also conducted manual evaluation on prompt-response pairs across languages and task categories. Scores are between 1-5 (higher the better). Model names were anonymised during the evaluation. We currently limit the evaluation to 8 languages and plan to extend it.
How to Access the Model?
Chat Application
Users can directly access the model on our chat application here: chat.olakrutrim.com/home
API Integration
Developers can integrate the model into their applications via the model API available on Krutrim cloud.
Run locally
Please visit the Krutrim-2 repository or Krutrim-2 HF page for details on running the model locally.
License
Authors: Vivek Dahiya, Palash Kamble, Aditya Kallappa, Souvik Rana, Manoj Guduru, Neel Rachamalla, Guo Xiang, Jay Piplodiya, Yong Tong Chua, Ashish Kulkarni, Hareesh Kumar, Chandra Khatri