Krutrim Tokenizer


The Krutrim Tokenizer, built using SentencePiece BPE, is optimized for Indian languages, English, and code, addressing challenges like rich morphology, complex scripts, and code-mixing. By employing extensive data cleanup and a balanced vocabulary, it ensures efficient tokenization for improved NLP performance across diverse Indian languages.
Introduction
Tokenization is a crucial step in Natural Language Processing (NLP), as it directly impacts the performance of language models. Most existing tokenizers are optimized for high-resource languages like English, leaving Indian languages underrepresented. To address this gap, we developed the Krutrim Tokenizer, which employs SentencePiece Byte Pair Encoding (BPE) to efficiently tokenize Indian languages along with English and code data.
Why Tokenization Matters for Indian Languages
Indian languages have unique characteristics, such as:
- Rich morphology: Words inflect heavily based on tense, gender, and plurality.
- Complex scripts: Many scripts, such as Devanagari and Tamil, lack whitespace-based word separation and sometimes complex words are formed due to sandhi/samas and other grammatical rules.
- Code-mixing: Frequent blending of English and native languages in text.
- Low-resource availability: Limited annotated datasets compared to English.
A standard tokenizer may not handle these challenges effectively, leading to suboptimal performance in NLP tasks.
The Krutrim Tokenizer: Built for India
The Krutrim Tokenizer was designed with the following principles:
- SentencePiece BPE-based: Unlike traditional word or character-based tokenization, BPE captures frequent subword units, making it efficient for Indian languages with complex morphology.
- Data Cleanup: Extensive preprocessing was performed to retain only essential Indian language data, reducing noise from unnecessary symbols and characters.
- Balanced Vocabulary: The training was done on data carefully curated to cover all major Indian languages, English, and code.
Training Methodology
- Data Collection: Multilingual text corpus sourced from books, websites, and government documents.
- Cleaning & Preprocessing: Removed unwanted symbols, normalized scripts, and retained high-quality text.
- Training on SentencePiece BPE: The model was trained to learn efficient subword representations.
- Evaluation: Compared against existing tokenizers for efficiency and performance.
Samples
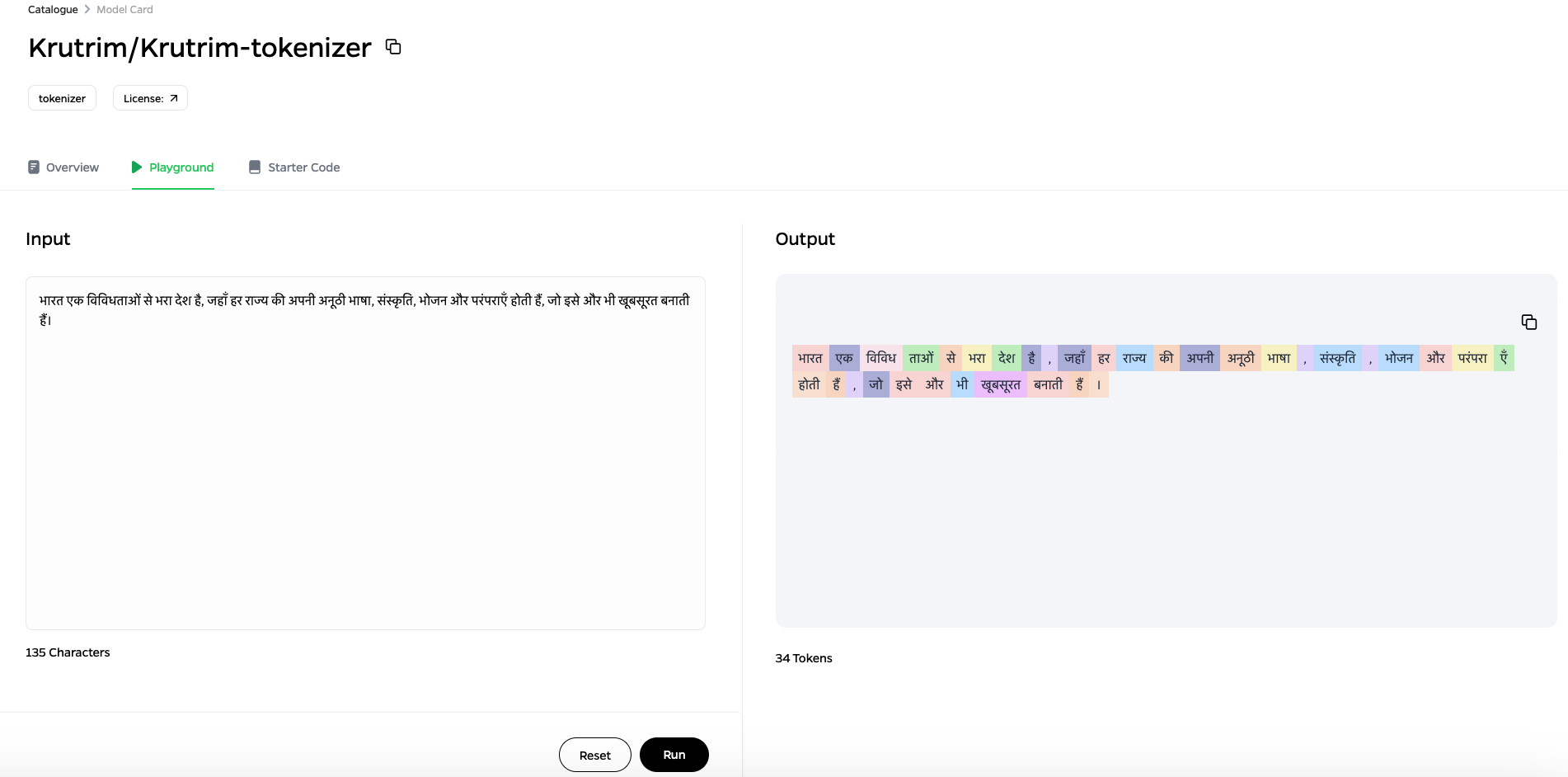
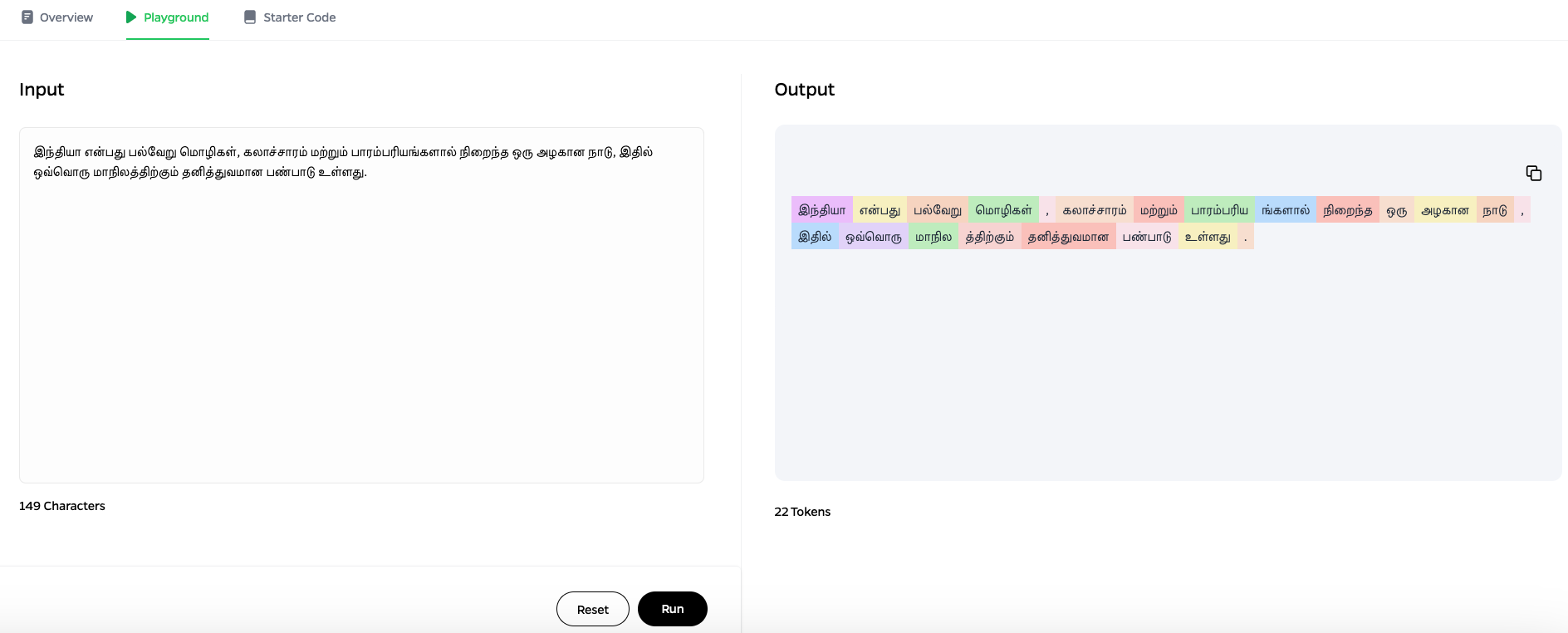
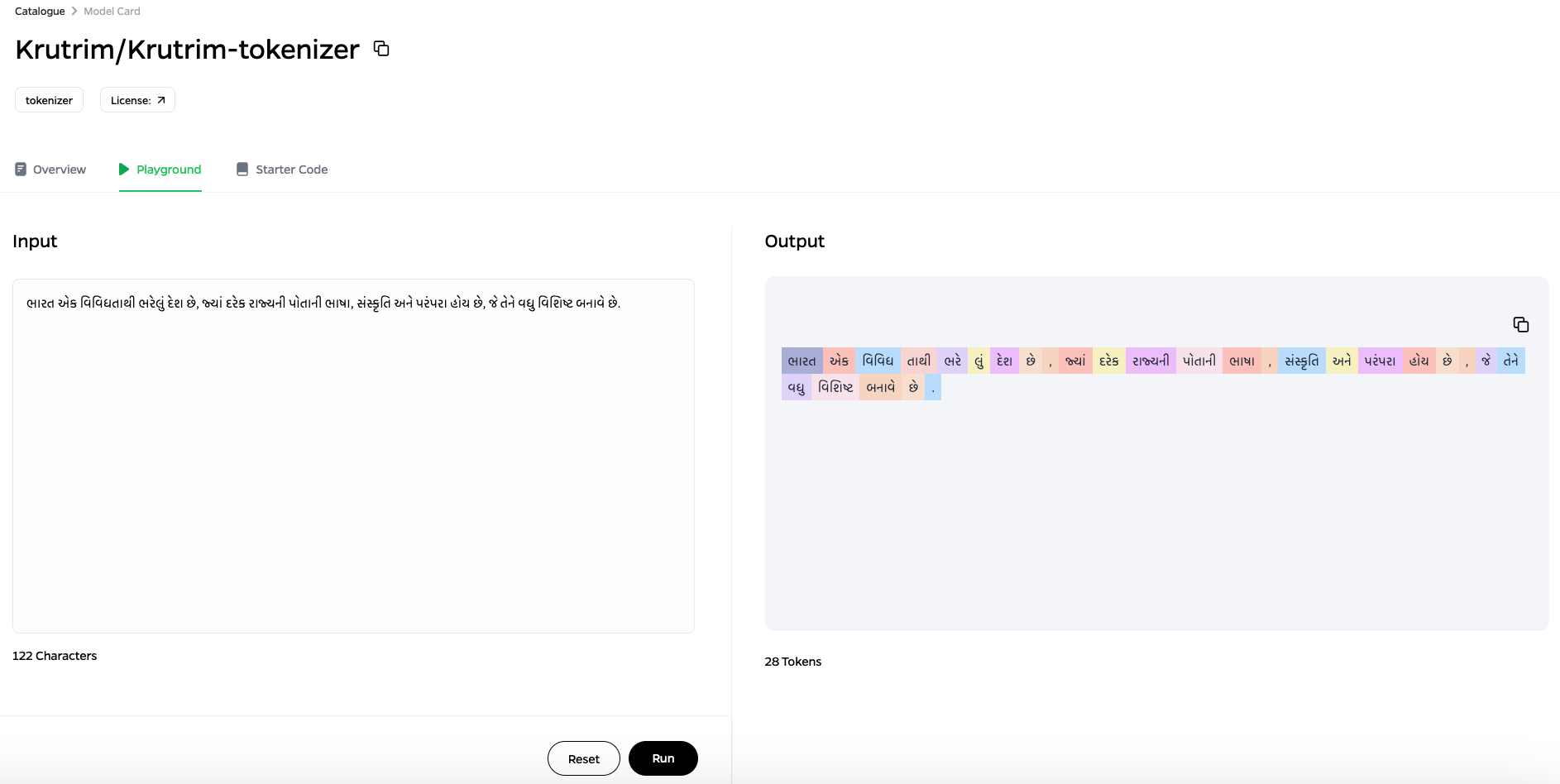
Comparative Performance
A comparative analysis was conducted, evaluating the Krutrim Tokenizer against other Indic tokenizers. The results (visualized in the attached plots) indicate that:
- Krutrim Tokenizer performs significantly better in terms of tokenization efficiency.
- It produces shorter sequences, reducing computational overhead in NLP models.
- It captures Indian language nuances better than generic tokenizers.
The comparison plot highlights Krutrim's performance against various tokenizers like GPT-4o, Gemma, Mistral-Nemo, Llama-3, Sarvam-2B, Sutra, and DeepSeek-R1. The lower scores indicate better tokenization efficiency, demonstrating how our approach effectively balances multilingual support while optimizing token usage for Indian languages.
Plot:

Accessing Krutrim Tokenizer on Krutrim Cloud
https://www.olakrutrim.com/language-hub
Conclusion
The Krutrim Tokenizer is a step forward in optimizing NLP models for Indian languages. By leveraging SentencePiece BPE, it efficiently tokenizes multilingual text, making it ideal for tasks such as language modeling, OCR, and machine translation. As we continue refining our models, this tokenizer serves as a foundational tool for building robust Indic NLP applications.
Authors: Aditya Kallappa, Palash Kamble, Akshat Patidar, Abhinav Ravi, Ashish Kulkarni, Chandra Khatri